编码数据的格式
程序通常(至少)使用两种形式的数据:
- 内存中,数据存储在对象、结构体、列表、数组、散列表、树等中。这些数据结构针对CPU的高效访问和操作做了优化(通常使用指针)。
- 如果要将数据写入文件,或者通过网络发送,则必须将其 编码(encode) 为某种自包含的字节序列(如:json文档)。由于每个进程都有自己的独立的地址空间,一个进程中的指针对任何其他进程都没有意义,所以这个字节序列表示 与 通常在内存中使用的数据结构完全不同 (除了一些特殊情况外,如某些内存映射文件或直接压缩数据上的操作)。
所以,两者表示之间,需要进行某种类型的翻译。
- 从内存中表示 —> 字节序列 : 编码(Encoding)(也称 序列化(serialization) 、或 编组(marshalling))
- 字节序列 —> 内存: 解码(Decoding) (也称 解析(Parsing),反序列化(deserialization), 反编组(unmarshalling)
ps1:编码(encode)和 加密(encryption) 无关。
ps2:Marshal 与 Serialization 的区别:Marshal 不仅传输对象的状态,而且会一起传输对象的方法(相关代码)。
JSON、XML和二进制变体
JSON,XML 和 CSV 属于文本格式,因此具有人类可读性(尽管它们的语法是一个热门争议话题)。除了表面的语法问题之外,它们也存在一些微妙的问题:
- 数字编码的模糊。XML 和 CSV 无法处理区分数字和字符串(除非使用外部模式)。JSON 虽然可以区分数字和字符串,但是不能区分整数和浮点数,且不能指定精度。处理大数时这是个问题。大于 2^53 的整数无法使用 IEEE754 双精度浮点数表示。
- JSON 和 XML 对 Unicode 字符串有很好的支持,但是它们不支持二进制数据(即不带字符编码的字节序列)。
- XML和JSON都有可选的模式支持。这些模式语言非常强大,因此学习和实现它们相对复杂。XML模式的使用相对广泛,但许多基于JSON的工具并不使用模式。由于数据的正确解释(例如数字和二进制字符串)取决于模式中的信息,不使用XML/JSON模式的应用程序需要在编码/解码逻辑中可能硬编码适当的处理方式。
- CSV(逗号分隔值)没有任何模式,因此应用程序需要自行定义每行和每列的含义。如果应用程序更改导致添加新的行或列,您必须手动处理这些更改。CSV格式也比较模糊(如果值中包含逗号或换行符会发生什么?)。虽然它的转义规则已经正式规定,但并非所有解析器都正确地实现了这些规则。
尽管存在这些缺陷,但 JSON、XML 和 CSV 对很多需求来说已经足够好了。它们很可能会继续流行下去,特别是作为数据交换格式来说(即将数据从一个组织发送到另一个组织)。在这种情况下,只要人们对格式是什么意见一致,格式有多美观或者效率有多高效就无所谓了。让不同的组织就这些东西达成一致的难度超过了绝大多数问题。
二进制编码
对于仅在组织内部使用的数据,使用最通用的编码格式的压力较小。例如,您可以选择更紧凑或更快速解析的格式。对于小型数据集,这些改进可能微不足道,但一旦涉及到大量的数据(以TB为单位),数据格式的选择就会产生重大影响。
JSON相比XML较为简洁,但与二进制格式相比,它们仍然使用了大量的空间。这一观察结果导致了针对 JSON(例如MessagePack、BSON、BJSON、UBJSON、BISON和Smile)和XML(例如WBXML和Fast Infoset)的大量二进制编码的开发。这些格式在各个领域中被采用,但没有一个像JSON和XML的文本版本那样被广泛采纳。
由于它们没有规定模式,所以它们需要在编码数据中包含所有的对象字段名称。
eg: 示例 json 文档,以下会用多种格式对这段数据进行编码
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}MessagePack 编码
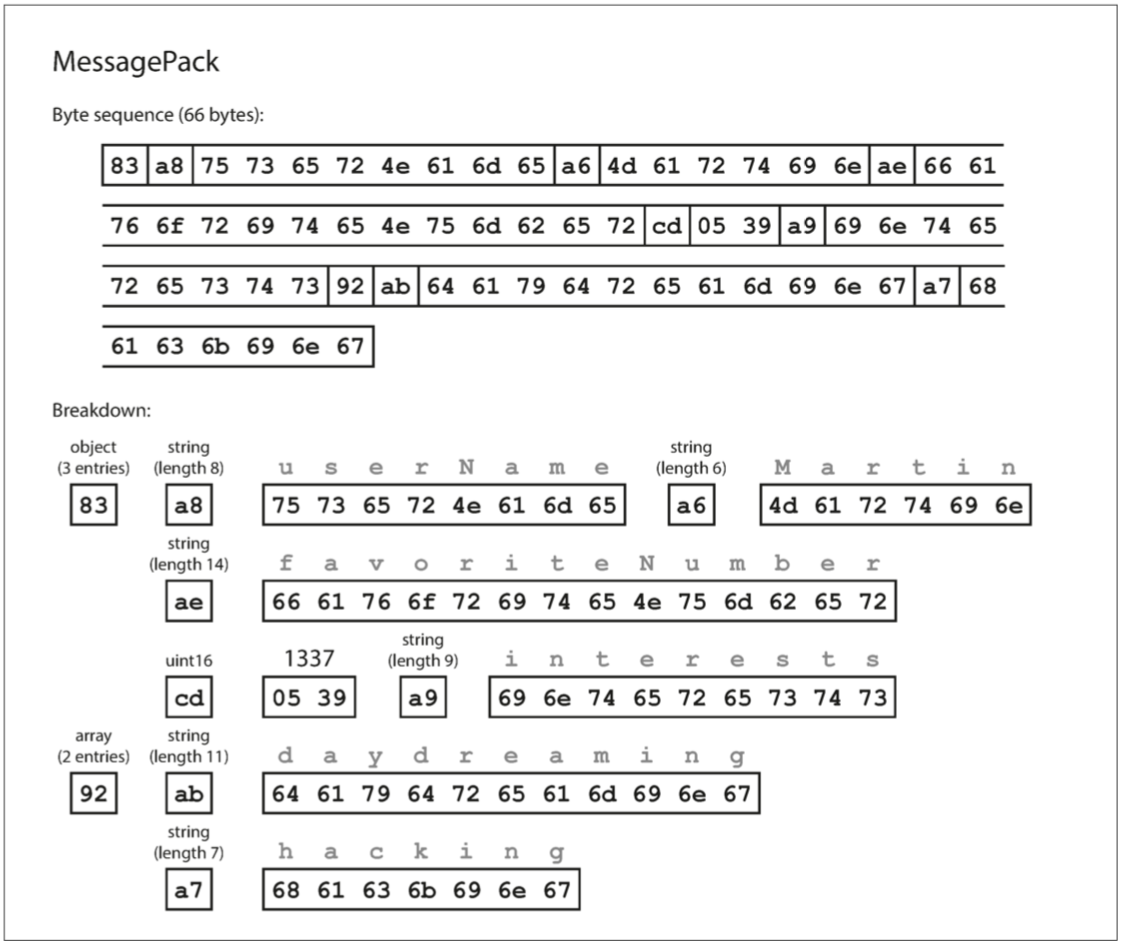
- 第一个字节
0x83表示接下来是 3 个字段(低四位 =0x03)的 对象 object(高四位 =0x80)。 (如果想知道如果一个对象有 15 个以上的字段会发生什么情况,字段的数量塞不进 4 个 bit 里,那么它会用另一个不同的类型标识符,字段的数量被编码两个或四个字节)。 - 第二个字节
0xa8表示接下来是 8 字节长(低四位 =0x08)的字符串(高四位 =0x0a)。 - 接下来八个字节是 ASCII 字符串形式的字段名称
userName。由于之前已经指明长度,不需要任何标记来标识字符串的结束位置(或者任何转义)。 - 接下来的七个字节对前缀为
0xa6的六个字母的字符串值Martin进行编码,依此类推。
二进制编码长度为 66 个字节,仅略小于文本 JSON 编码所取的 81 个字节(删除了空白)。所有的 JSON 的二进制编码在这方面是相似的。空间节省了一丁点(以及解析加速)是否能弥补可读性的损失,谁也说不准。
Thrift 与 Protocol Buffers
Facebook 的 Thrift 和 Google 的 Protocol Buffers 都需要一个模式来编写数据:
struct Person {
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}Protocol Buffers 的模式看起来是非常相似
message Person {
required string user_name = 1;
optional int64 favorte_number = 2;
repeated string interests = 3;
}它们都带有一个代码生成工具,根据类似以上示例的模式定义,生成各种编程语言实现该模式的类。你的应用程序可以调用生成的代码对模式的记录进行编码和解码。编码后的数据如下:
Thrift 提供两种不同的二进制编码格式(迷之操作),BinaryProtocol 和 CompactProtocol。(ps: 实际上,Thrift 有三种二进制协议:BinaryProtocol、CompactProtocol 和 DenseProtocol,尽管 DenseProtocol 只支持 C ++ 实现,所以不算作跨语言。 除此之外,它还有两种不同的基于 JSON 的编码格式。 真逗!)
BinaryProtocol :
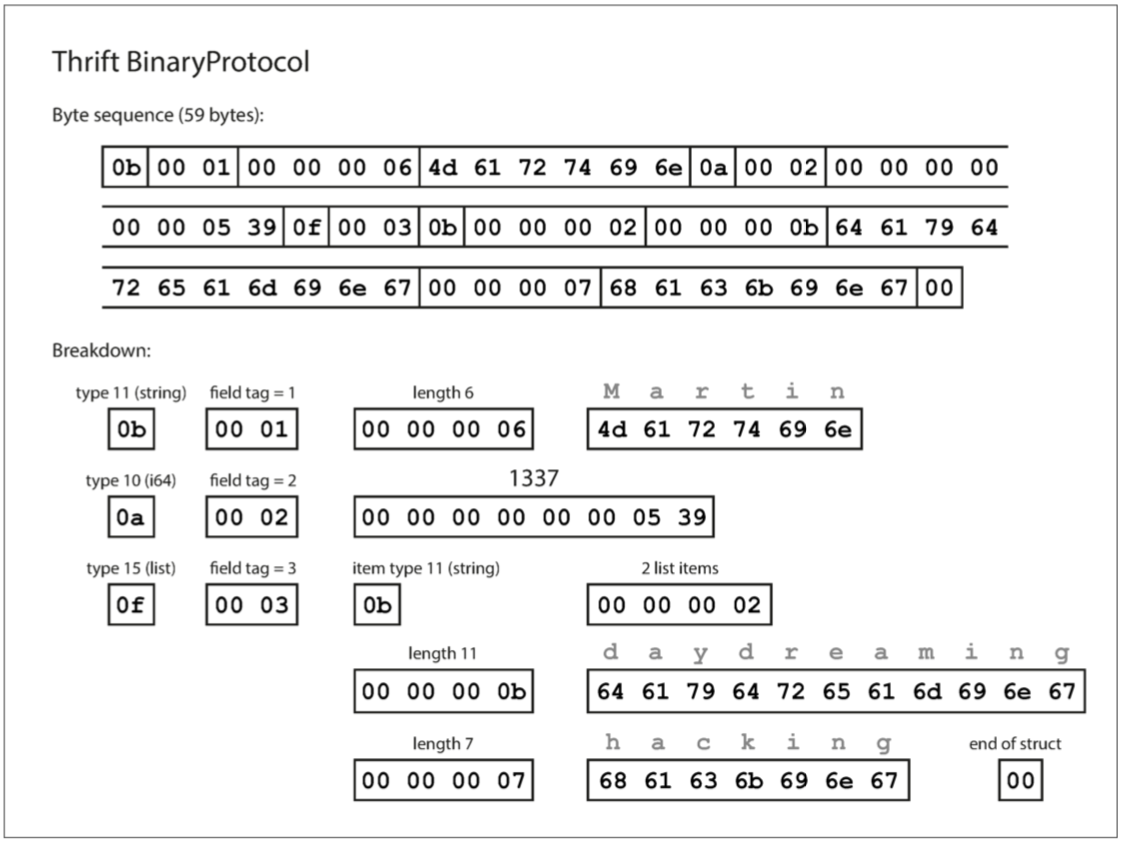
不必传递字段全名,只需传递模式定义中的数字编号,所以更紧凑。
CompactProtocol :
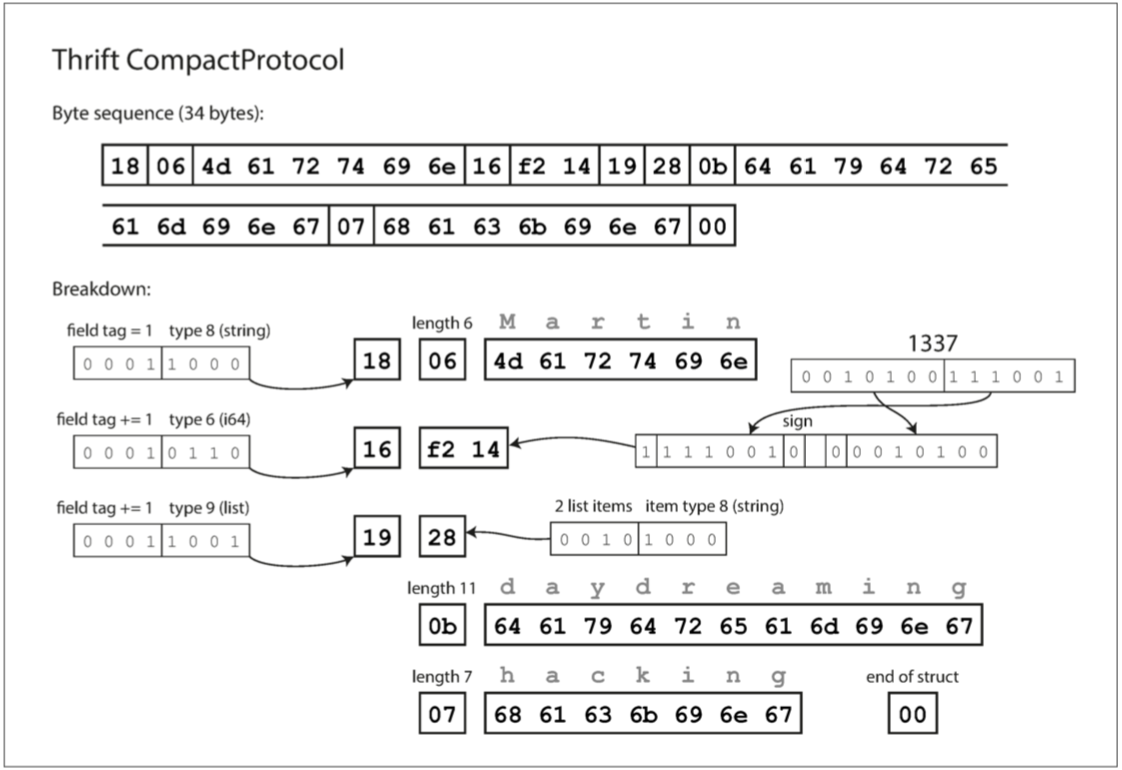
字段类型和标签号打包到单个字节中;可变长度的整数。数字 1337 不是使用全部八个字节,而是用两个字节编码,每个字节的最高位用来指示是否还有更多的字节。这意味着 - 64 到 63 之间的数字被编码为一个字节,-8192 和 8191 之间的数字以两个字节编码,等等。较大的数字使用更多的字节。
Protocol Buffers 编码:
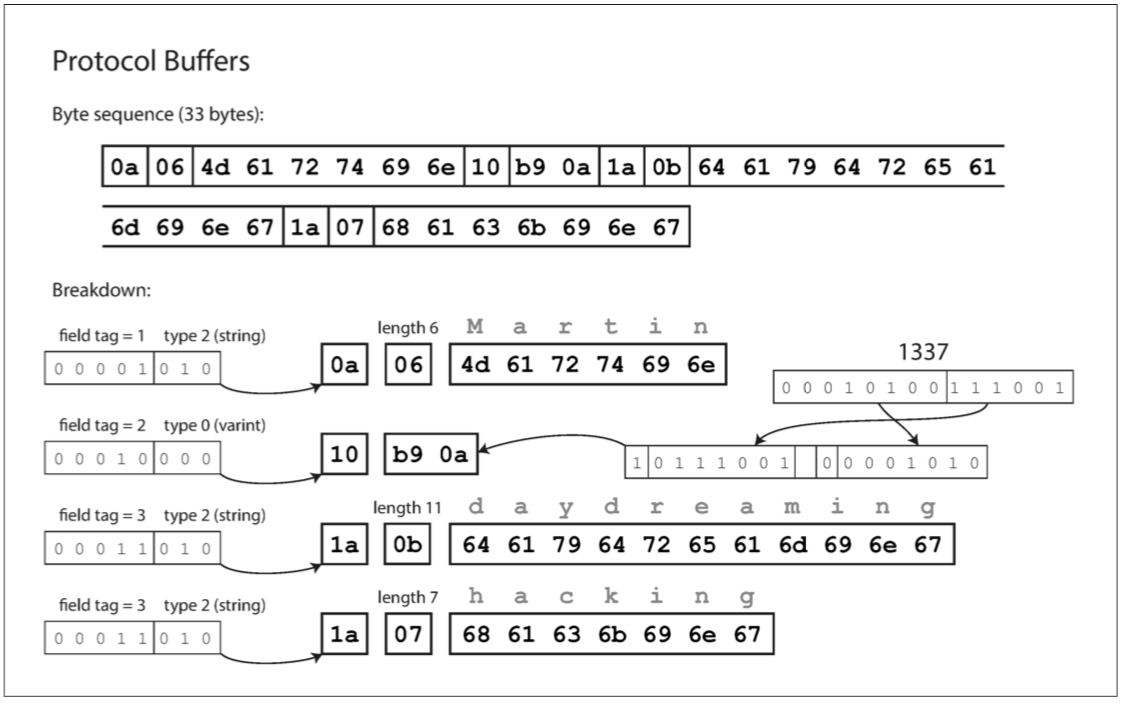
需要注意的一个细节:在前面所示的模式中,每个字段被标记为必需或可选,但是这对字段如何编码没有任何影响(二进制数据中没有任何字段指示某字段是否必须)。区别在于,如果字段设置为 required,但未设置该字段,则所需的运行时检查将失败,这对于捕获错误非常有用。
字段标签和模式演变
如上例子,一个编码的记录就是一堆编码过的字段,每个字段使用 标签号(模式定义中的数字1,2,3) 唯一标识,并且标注一个数据类型(e.g. string 或 int)。如果一个字段没有设置值,编码是即可忽略它。也就是说你可以改变字段的名字,但是不能改变字段的标签号,否则将影响已经编码的数据。
新增字段,给新字段设置标签号即可。旧代码(不知道有新字段)尝试读取包含新字段的数据时,它不能识别新的标签号,直接忽略即可。数据类型注释会告诉解析器它需要跳过多少字节。这保证了 向前兼容:(新代码产生的编码后数据可以被旧代码读取)。
对于向后兼容,因为每个字段都有一个唯一的标签号且标签号代表这相同的意思,旧代码产生的编码后数据总是能被新代码读取。唯一需要注意的是,你不能设置字段是 required 的。如果一个新增字段被设置为 必须的 ,新代码读取时将检查该字段是否存在,而旧代码编码的数据压根不知道新字段的存在。因此,为了保持向后兼容性,在模式初始化部署之后,每个新增的字段必须是 optional 或者设置默认值。
删除一个字段与添加一个字段类似,只是向前兼容和向后兼容的关注点被颠倒了。这意味着你只能删除一个可选的字段(必需字段永远不能删除),而且你不能再次使用相同的标签号码(因为你可能仍然有数据写在包含旧标签号码的地方,新代码已经忽略了该字段)。
数据类型和模式演变
改变数据类型也是可行的,但是有一个风险,值将失去精度或者被截断。例如,你把 i32 转为 i64, 新代码可以很容易读取旧数据(前32位用零填充)即 向后兼容。然而新代码产生的 i64 数据,旧代码在读取时是按照 i32 读取的,会被截断,即没有 向前兼容。
Protobuf 没有 list 或 array 的数据类型,取而代之的是一个 repeated (和 required 和 optional 同一个等级 ), 一个字段被定义为 repeated , 意味着,相同标签号的字段在记录出现了多次 。这种设计,对于将 optional (单值)字段变更为 repeated (多值)字段,非常有用。新代码在读取 旧数据 时,会看到一个出现了 1次或0次的元素(取决于旧数据字段值是否被设置);旧代码读取新数据时,只能读取到列表的最后一个元素。
Thrift 有专门的列表数据类型,该数据类型使用列表元素的数据类型作为参数。这不允许像 Protocol Buffers 那样从单值到多值的演化,但它具有支持嵌套列表的优势。
Avro
Apache Avro 是作为 Hadoop 的子项目,在 2009 年开始。
有两种模式: Avro IDL 用于人工编辑; 基于json 更易于机器读取。
上述例子,使用 Avro IDL 编写,如下:
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}
等价的 JSON 展示这个 模式如下:
{
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favoriteNumber", "type": ["null", "long"], "default": null},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}其编码字节如下所示
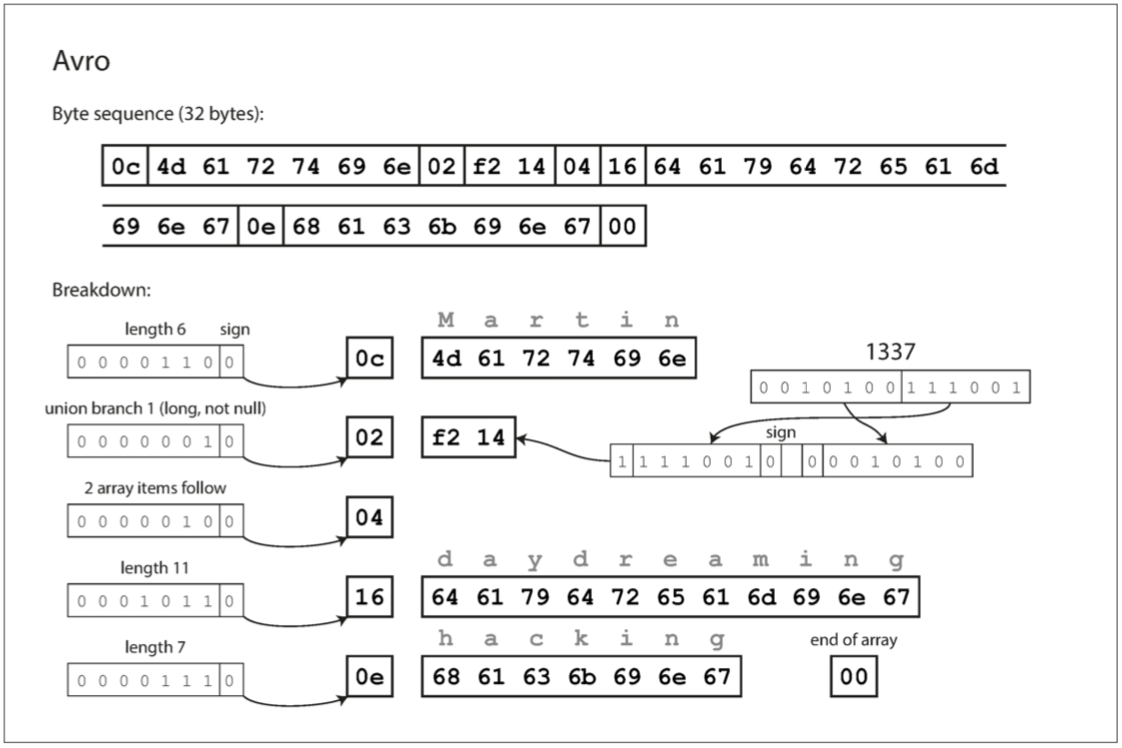
有几点有趣的如下:
- 该模式没有标签序号
- 字节序列既没有字段的唯一标识也没有字段的数据类型,只是一串连在一起的值
- 如上一个 string 类型的字段,只有一个长度前缀,后跟着UTF-8 字节,编码数据中没有任何告诉你这是一个字符串。它可以被当成整数,或者其他的数据类型
- 整数使用和 Thrift 的 CompactProtocol 相同的可变长度的方式编码
- 为了解析二进制数据,你应该按照模式中定义的顺序和数据类型遍历各个字段,这意味着,只有当读取数据和写入数据使用 完全相同的模式 时,二进制数据才能被正确解析。
reader schema 和 writer schema
writer’s schema: 当一个应用想编码一些数据(写入到文件、数据库,或者通过网络发送等),应用会使用任一版本的模式(它知道的,例如被编译到应用中的)来编码数据。
reader’s schema:当一个应用想解码一些数据(从文件、数据库读取,或者从网络接收等),它期待数据遵循一些模式,这叫做读者模式。这个模式是应用程序代码所依赖的,也就是说,代码可能在应用程序的构建过程中根据这个模式生成。
Avro 的核心思想时,reader 模式和 writer 模式不必完全相同,只需要兼容。当数据解码(读取)时,Avro库通过并排查看 Writer 和 Reader模式,并将数据从 Writer 模式转换到Reader模式。以下是个示例:
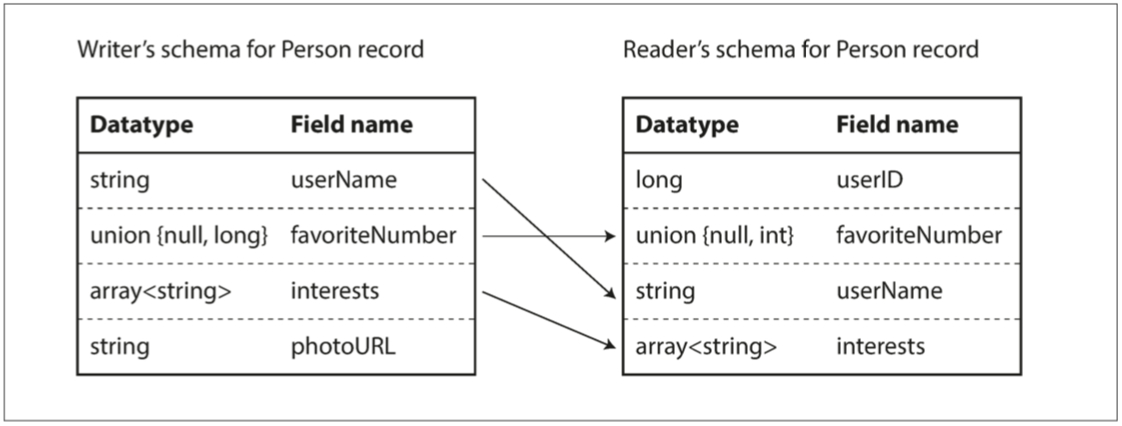
- 顺序不同,没问题
- writer 中有 ,reader 中没有,忽略它
- writer 中没有,reader 中要获取,则使用 reader 模式中的默认值
模式演变规则
对于 Avro, 向前兼容意味着你有一个新版本的模式被作为writer,而旧版本的模式作为 reader。相反,向后兼容意味着,你新版本的模式作为 reader,旧版本作为writer。
为了保证兼容性,你只能添加或删除有默认值的字段。这时,新字段会存在在新模式中而非旧模式中,当新模式的reader读取旧模式写入的记录时,缺少的字段填充默认值。
Avro 中如果允许一个字段为 null,则必须使用联合类型。如:union {null, long, string} 表示 field 可以是 null 、长整型和字符串,且默认值为 null(Avro 的限制默认值必须为联合的第一分支)。
Avro 没有 optional 和 required ,因为它有联合类型和默认值。
只要 Avro 可以支持相应的类型转换,就可以改变字段的数据类型。更改字段的名称也是可能的,但有点棘手:Reader 模式可以包含字段名称的别名,所以它可以匹配旧 Writer 的模式字段名称与别名。这意味着更改字段名称是向后兼容的,但不能向前兼容。同样,向联合类型添加分支也是向后兼容的,但不能向前兼容。
writer模式到底是什么
对于一段特定的编码数据,Reader 如何知道其 Writer 模式?我们不能只将整个模式包括在每个记录中,因为模式可能比编码的数据大得多,从而使二进制编码节省的所有空间都是徒劳的。
答案是 Avro 使用上下文:
很多记录的大文件
Avro 的一个常见用途,尤其在 Hadoop 环境中——用于存储数百万条记录的大文件,所有记录采用相同的模式进行编码。在这种情况下,该文件的作者可以在文件的开头只包含一次 Writer 模式。 Avro 指定了一个文件格式(对象容器文件)来做到这一点。
独立写入记录的数据库
在一个数据库中,不同的记录可能会在不同的时间点使用不同的 Writer 模式来写入 - 你不能假定所有的记录都有相同的模式。最简单的解决方案是在每个编码记录的开始处包含一个版本号,并在数据库中保留一个模式版本列表。Reader 可以获取记录,提取版本号,然后从数据库中获取该版本号的 Writer 模式。使用该 Writer 模式,它可以解码记录的其余部分(例如 Espresso 就是这样工作的)。
通过网络连接发送的记录
当两个进程通过双向网络连接进行通信时,他们可以在连接设置上协商模式版本,然后在连接的生命周期中使用该模式。 Avro RPC 协议就是这样工作的。
存储模式版本的数据库很有用,它可以让你有机会检查文档的模式兼容性。版本号可以递增,也可以hash。
动态生成的模式
Avro 不含任何标签号码,这使得 Avro 对动态生成模式更友善。
假如, 你想把一个关系数据库的内容转存到一个二进制文件中,使用 Avro 可以很容易生成一个模式,并用该模式对内容进行编码,然后将其存储到 Avro 对象容器文件中(数据库的列名,就映射为Avro模式中的字段名)。
现在,数据库模式发生变化(新增或删除了列),则可以从新数据库模式生成新的Avro模式,并使用新模式导出数据。更新的 Writer 模式仍然可以与旧的 Reader 模式匹配。
如果使用 Thrift 或 Protocol Buffers,则字段标签可能必须手动分配:每次数据库模式更改时,管理员都必须手动更新从数据库列名到字段标签的映射(这可能会自动化,但模式生成器必须非常小心,不要分配以前使用的字段标签)。这种动态生成的模式根本不是 Thrift 或 Protocol Buffers 的设计目标,而是 Avro 的。
代码生成
Thrift 和 Protobuf 依赖于代码生成。对于静态类型编程语言的用户来说,从模式生成代码的能力是有用的,因为它可以在编译时进行类型检查。对动态类型的语言,生成代码没有太多意义。
Avro 为静态类型编程语言提供了可选的代码生成功能,但是它也可以在不生成任何代码的情况下使用。如果你有一个对象容器文件(它嵌入了 Writer 模式),你可以简单地使用 Avro 库打开它,并以与查看 JSON 文件相同的方式查看数据。该文件是自描述的,因为它包含所有必要的元数据。(特别适合动态类型的数据处理语言如 Apache Pig )。
模式的优点
- 它们可以比各种 “二进制 JSON” 变体更紧凑,因为它们可以省略编码数据中的字段名称。
- 模式是一种有价值的文档形式,因为模式是解码所必需的,所以可以确定它是最新的(而手动维护的文档可能很容易偏离现实)。
- 维护一个存储模式的数据库允许你在部署任何内容之前检查模式变更的向前和向后兼容性。
- 对于静态类型编程语言的用户来说,从模式生成代码的能力是有用的,因为它可以在编译时进行类型检查。