Docker容器内部抓包
很多docker容器为了轻量化,都不包含一些基础命令,如ip ,address,tcpdump 等,这给调试容器的网络带来了麻烦。
其实我们可以通过 命令进入容器的网络命名空间,使用宿主机的命令调试容器网络。
很多docker容器为了轻量化,都不包含一些基础命令,如ip ,address,tcpdump 等,这给调试容器的网络带来了麻烦。
其实我们可以通过 命令进入容器的网络命名空间,使用宿主机的命令调试容器网络。
数据库分布在多台设备上的好处:
扩展负载
今天发现早上登录服务器,查看日志有大量ssh登录的爆破,所以先限制root用户不允许远程登录,再使用Fail2Ban自动封锁ip限制一下。
记录如下:
很多内网环境需要离线安装软件,就需要我们在可以上网的服务器上将需要安装的软件的相应安装包及其依赖下载下来,传输到离线机器,再安装。其中下载和处理依赖关系可能比较麻烦,所以本文特做记录。
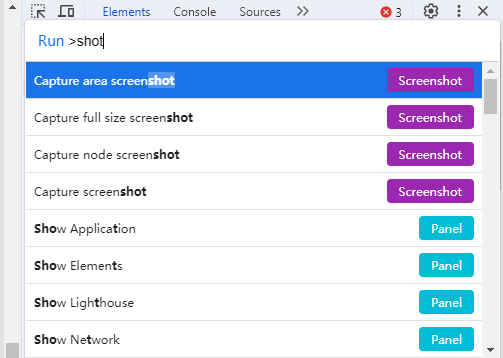
F12 打开开发者模式,选择需要截图的节点,ctrl+shift+p 打开运行栏,搜索 shot,选择 Capture node screenshot,如下图:
如果截取手机或平板模式的图,先点击左上角的 Toggle device toolbar ( Ctrl + Shift + M )选择合适的设备,再进行上面步骤。
代码实现如下:
数据在不共享内存的进程传递,就需要编码为字节序列。有多种方式。
兼容性 实际描述了 编码数据的进程 和 解码数据的进程 之间的关系。它对 可演化性(允许你升级系统的部分,而不必全部升级) 非常重要。
程序通常(至少)使用两种形式的数据:
所以,两者表示之间,需要进行某种类型的翻译。